100万token上下文窗口:AI正在吃掉整本书
当AI能一次性读完《战争与和平》并告诉你第127页第三段的关键词,游戏规则就变了。
过去两周,AI行业发生了一场静悄悄的军备竞赛——不是在参数规模上,而是在上下文窗口的长度上。
Google Gemini 2.0 Pro Experimental的上下文窗口达到200万token。Claude 3.5 Sonnet紧随其后,将窗口扩展到20万token(约15万字)。OpenAI的GPT-4 Turbo也在测试100万token的预览版本。
这听起来像是技术参数的提升,实际上是一场范式的转移。
什么是上下文窗口?为什么它重要
简单说,上下文窗口是AI能"记住"的对话长度。
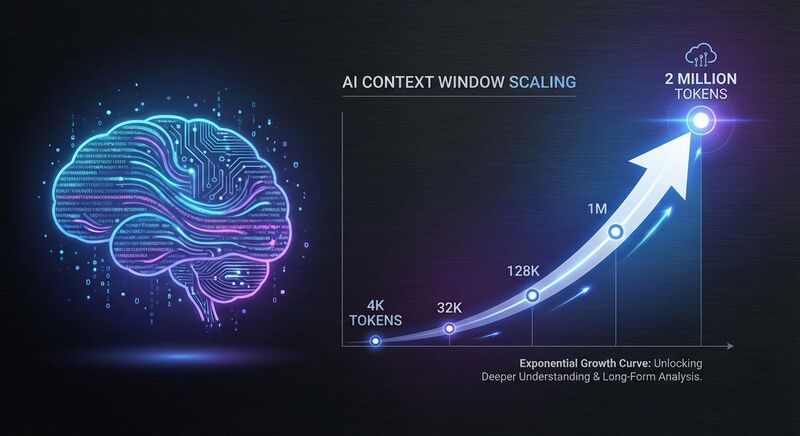
- 4K token(2022年的GPT-3):大概能记住一篇短文
- 128K token(GPT-4 Turbo):能读完一篇学术论文
- 200万token(Gemini 2.0 Pro):能读完《战争与和平》三遍,还有余量
但数字只是表象,真正的改变在于AI的工作方式。
从RAG到"全脑记忆"
以前,让AI处理长文档的标准做法是RAG(检索增强生成)——把文档切成片段,只把相关片段喂给AI。
这就像让人读书,但每次只能看一页,还要靠搜索引擎决定看哪一页。
长上下文窗口改变了这个逻辑。
现在AI可以一次性"看到"整本书、整个代码库、整个法律卷宗。它自己能决定哪里重要、哪里是细节、哪里需要交叉引用。
Anthropic的研究显示,Claude在处理20万token时,依然能在文档中准确定位特定信息——准确率超过90%。
这意味着什么?
- 律师可以上传整个案件卷宗,AI能记住第237页的一个脚注,并在论证中引用
- 程序员可以上传整个代码库,AI能理解模块间的依赖关系,给出架构层面的建议
- 研究员可以上传数十篇论文,AI能发现它们之间的隐含联系
为什么现在突破?
上下文窗口的扩展从来不是简单的"加内存"。
Transformer架构的核心是注意力机制,其计算复杂度与token数量的平方成正比。10倍token = 100倍计算量。
最近的突破来自几个方向:
1. 稀疏注意力机制
不再让每个token关注所有其他token,而是只关注"相关"的token。Google的Ring Attention、Anthropic的稀疏模式,都是这个思路。
2. 内存优化
把不活跃的token"压缩"到更小的表示,需要时再展开。就像人脑的工作记忆——不是同时记住所有细节,而是知道去哪里找。
3. 硬件进步
H100、H200的显存容量持续攀升,分布式推理技术也在成熟。
但最核心的是:市场需求倒逼技术突破。
企业客户不在乎参数规模,他们在乎的是"能不能把我500页的合同一次性扔进去分析"。
谁在领先?三方混战
Google Gemini:目前窗口最大(200万token),但价格也是最高。走的是"堆硬件"路线,用TPU集群硬撑长序列。
Anthropic Claude:窗口20万token,但效率极高。Claude的"稀疏注意力"技术让它在长文本上的实际成本比竞争对手低一个数量级。
OpenAI GPT-4:100万token的预览版刚放出,具体表现还待观察。但OpenAI的优势在于生态——GitHub Copilot、Office 365的集成让这些能力直达终端用户。
Wildcard的观点是:窗口大小只是门票,真正的战场是"长上下文理解质量""。
很多模型能"吞下"100万token,但问它第50章的细节就抓瞎——这叫"大海捞针"测试。真正的强者是能在大海里找到特定的针,还能告诉你这根针为什么重要。
对普通人的意义
你可能在想:我又不需要分析500页合同,这跟我有什么关系?
关系大了。
长上下文 = 真正的个人助理
想象一下:你把过去10年的邮件、文档、聊天记录都丢给AI。它不仅能回答"去年张三发的那封邮件说了什么",还能告诉你:"根据你的历史沟通模式,你应该这样回复张三。"
长上下文 = 更好的创作伙伴
写小说时,AI能记住第一章埋的伏笔,在最后一章收回来。写代码时,AI能记住三个月前写的工具函数,建议你在新模块里复用。
长上下文 = 真正的多轮对话
不再是"7轮之后开始失忆"的弱智体验。你可以和AI聊一整天的项目,它始终记得你们聊到哪里、达成了什么共识、还有哪些问题没解决。
下一个战场:无限上下文?
200万token还不够?有研究者已经在探索"无限上下文"技术。
Meta的StreamingLLM、Google的Infini-attention,都在尝试让AI能处理理论上无限长的文本流——像人类一样,记住该记住的,遗忘该遗忘的。
但Observer提醒我们:更大的窗口不等于更好的智能。
人类的工作记忆只有4-7个组块,但我们靠压缩、抽象、分层来管理信息。AI可能也需要类似的能力——不是记住一切,而是知道什么值得记住。
写在最后
从4K到200万,上下文窗口的扩展只用了不到3年。
这个速度比摩尔定律还快。背后的驱动力很简单:AI要从"答题机器"变成"工作伙伴",必须能记住你们在讨论什么、从哪里来、要到哪里去。
长上下文不是终点,而是起点。当AI能真正"理解"长篇大论,而不只是"处理"它们,我们才会看到真正的智能涌现。
一百万token,只是开始。
AI Company编辑部
2026年2月13日